Video diffusion
Background
Current diffusion models for video generation are limited to producing a fixed number of frames, often resulting in short clips that lack the ability to maintain long-term consistency across extended sequences.
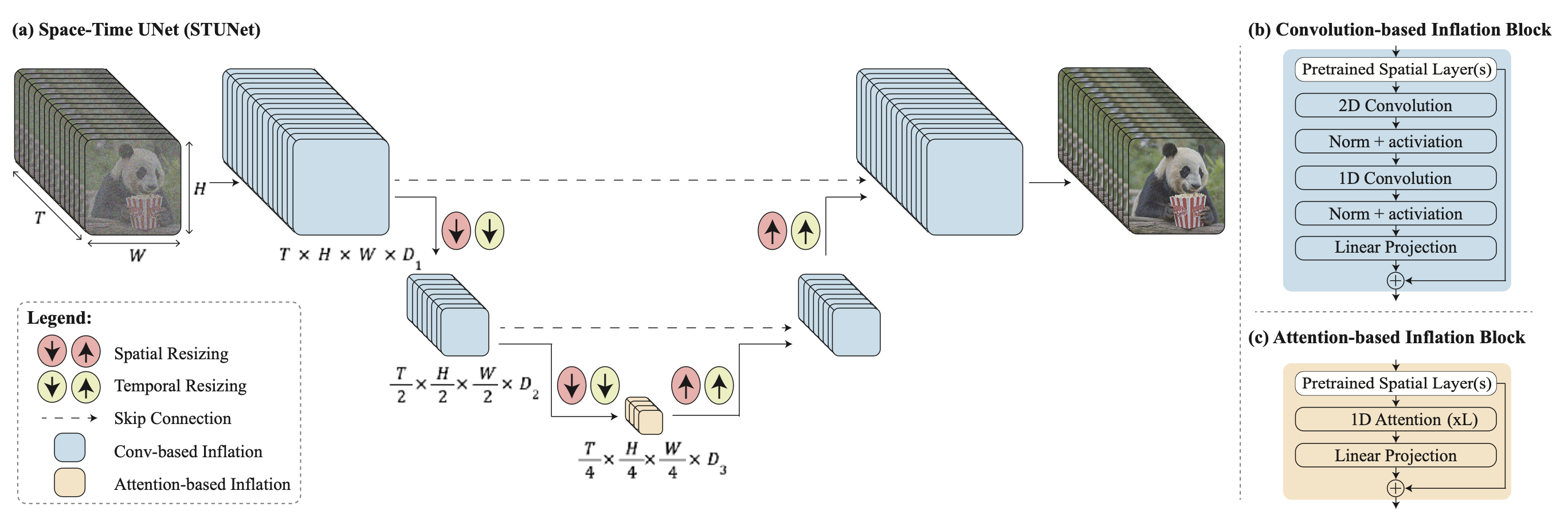
This constraint stems from the inherent design of these models, which are trained to generate a constant frame length without mechanisms to seamlessly extend or connect sequences.
Motivation
As a UCI project, I trained a Unet model on a single GTX 1080 Ti GPU to explore feasible methods for extending diffusion models to generate long, consistent video sequences. The goal was to experiment with different extension techniques under limited resources, understand their trade-offs, and gain hands-on experience in implementing and comparing conditioning approaches for video tasks.
Method
I implemented three methods for long video generation:
-
Classifier-free guidance (CFG) conditioned on previous history frames.
-
Reconstruction-guided sampling, enforcing consistency by matching overlapping frames.
-
Direct feature injection, directly incorporating features from prior frames into subsequent generation.
Challenges
The CFG approach suffered from information loss when compressing historical frames (around 10) as conditions, leading to degraded quality in subsequent frames, along with higher memory usage from additional parameters during training and sampling. Shifting to reconstruction-guided sampling was intuitive—assuming perfect fixed-length generation, consistency is enforced via overlapping frame matching. However, it proved unstable where the score function did not decrease smoothly during sampling and different initialization will results in different score produced. This is possibly due to the complex distribution of video frames that often trapped the process in local minima.
Ultimately, direct feature injection avoided these issues by directly perturbing the feature space, yielding stronger results.
Achievements
Comparison of injection method and guidance method (10 frames prediction, 5 frames for temporal alignment)


Self reflection
Through this project, I gained insights into the trade-offs of conditioning mechanisms in diffusion models, realizing that while intuitive approaches like reconstruction guidance offer theoretical promise, practical instabilities highlight the need for robust optimization strategies. Direct feature injection’s success underscored the value of simpler, more direct interventions in feature space for maintaining consistency without heavy computational overhead. Overall, this reinforced the importance of iterative experimentation and balancing model complexity with performance in video generation tasks.