Grokking - a possible way to achieve AGI
Introduction
Bigger is better. This phrase is so simple to be true, but it has been testified on AI. With the advent of ChatGPT, people realized that improving model’s performance can be so simple as increasing the size of model and dataset. The scaling laws - bigger and better - for model’s parameter and datasets have been studied thoroughly. However, there are few people studying how increasing training period can affect the model’s performance. Traditionally, if the model is trained for too long, it will enter what’s known as overfitting, a phenomenon that the train accuracy stays high while the validation accuracy drops. We would assume that this model failed to generalize over long period of time due to the poor performance on dataset the model has never seen before.
Grokking
But what happens if we keep on training after overfitting period? Will the test accuracy stays low? This is what researchers in Gork paper answer. They first have a small algorithmically generated datasets: binary operation of division mod 97. Then, they train a neural network on it, recording train accuracy and validation accuracy at each step. They found out that train accuracy reaches near 100% at around \(10^3\) steps. Validation accuracy, however, takes \(10^5\) steps to suddenly achieve near 100%. There’s no steady progress of val acc before \(10^5\).
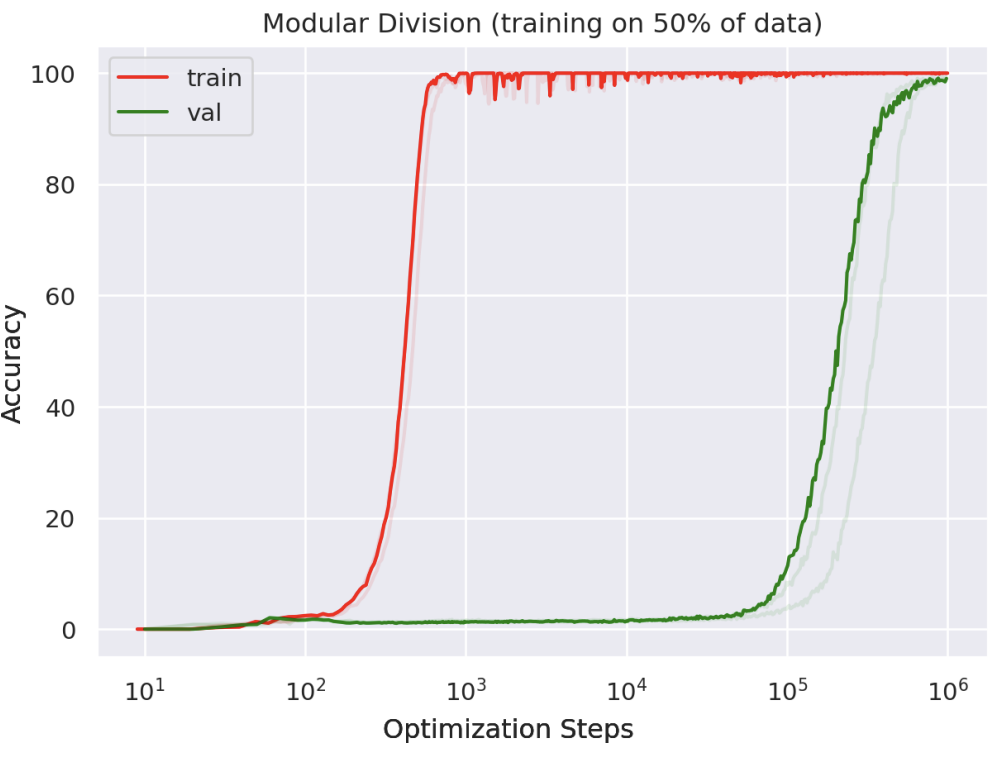
There’s a limitation in this paper. They only produce this phenomenon on simple dataset generated by modular function, which has strong data pattern. It’s not sure whether this phenomenon works on much more complex dataset, such as image and language. Even if it does work on complex dataset, it will surely take exceedingly long time to train and finally achieve grooking effect.
However, this is quite an interesting phenomenon and needs to be studied. If this grokking effect can happen in every model and every training process, it means that we don’t need additional tricks to maintain validation accuracy of the model. We just need the model to train for a long time, and it will generalize automatically. In that case, we are a step closer to AGI.
Grokking fast - low frequent gradient
As mentioned before, reaching grokking phenomenon can be time-consuming. For a simple dataset produced by modular, it takes \(1000\times\) for val acc to rise compared to train acc. For a larger complex dataset, the time may take too long to observe any rice of val accuracy.
The authors in Grokfast aimed to solve this problem by proposing to amplify slow gradients to accelerate grokking effect. They assumed that grokking effect was due to the slow-varying component of the gradient that results in long time grokking. They treat gradient as a discrete signal and apply low-pass filter to acquire gradients with low frequency, i.e. slow-varying. After that, use a hyper parameter to augment slow gradient and add it to total gradient. Overall, this paper proposes an optimization step to help the model achieve grokking faster.
There are of course some advantage and disadvantage of this method, which I will discuss later in the blog.
Conclusion
I believe grokking has the potential to achieve the same impact as the scaling laws. The latter emphasizes on the largeness on model while the first emphasizes on largeness of training time. Combining those two laws, I believe large language model can go further in generalization.