Grokking - a possible way to achieve AGI
As mentioned in previous blog, grokking is a phenomenon that extremely long training time leads to a sharp incease in val accuracy. Some researchers try to find a way to speed up the grokking phenomenon. GrokFast proposed a new optimizer to boost slow-varying component of the gradient as they hypothesized that it was a contributing factor to Grokking phenomenon.
Initially, I believe that GrokFast could be significant and was puzzled when there was only 1 citation currently. However, further testing on GrokFast shows that it was not capable enough to speed up generalization on test dataset. Default setup, using 3 layer and 200 hidden layer size can achieve good result on fast grokking, but other setup will result in much slower learning procedure, resulting much later increase in train accuracy and val accuracy. The test play results are presented below
GrokFast - testing
I first test the default setup mentioned above. The result is quiet amazing, as we can see the much earlier increase in val acc.
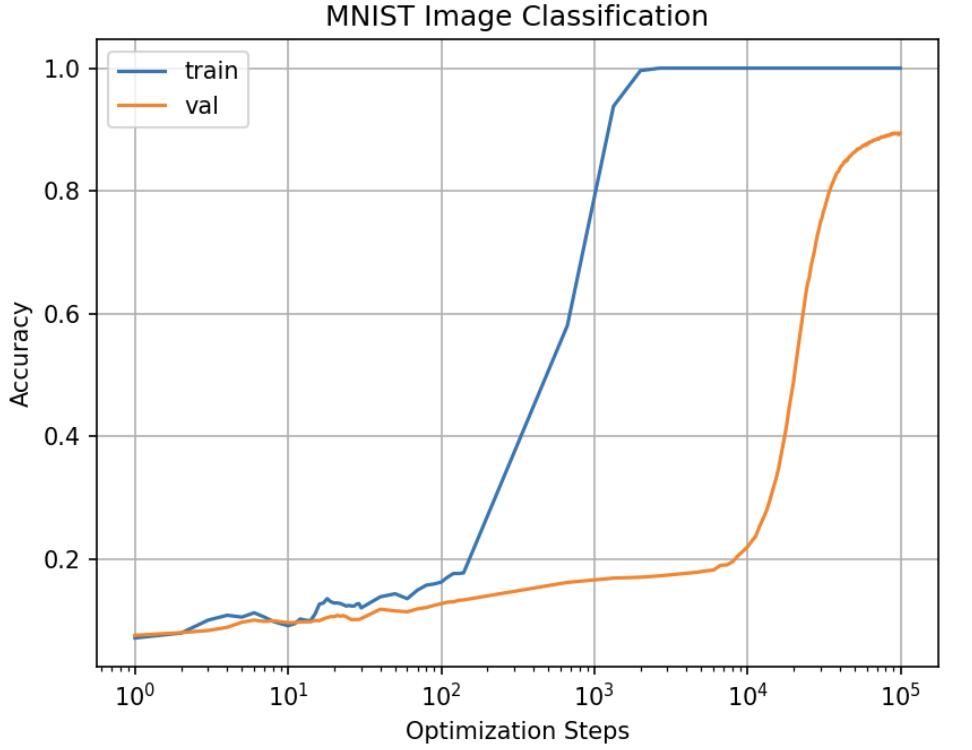
Later, I changed some parameters in GrokFast to test its general capability over all kinds of network. However, the result was not satsifying.
GrokFast - effect of network depth
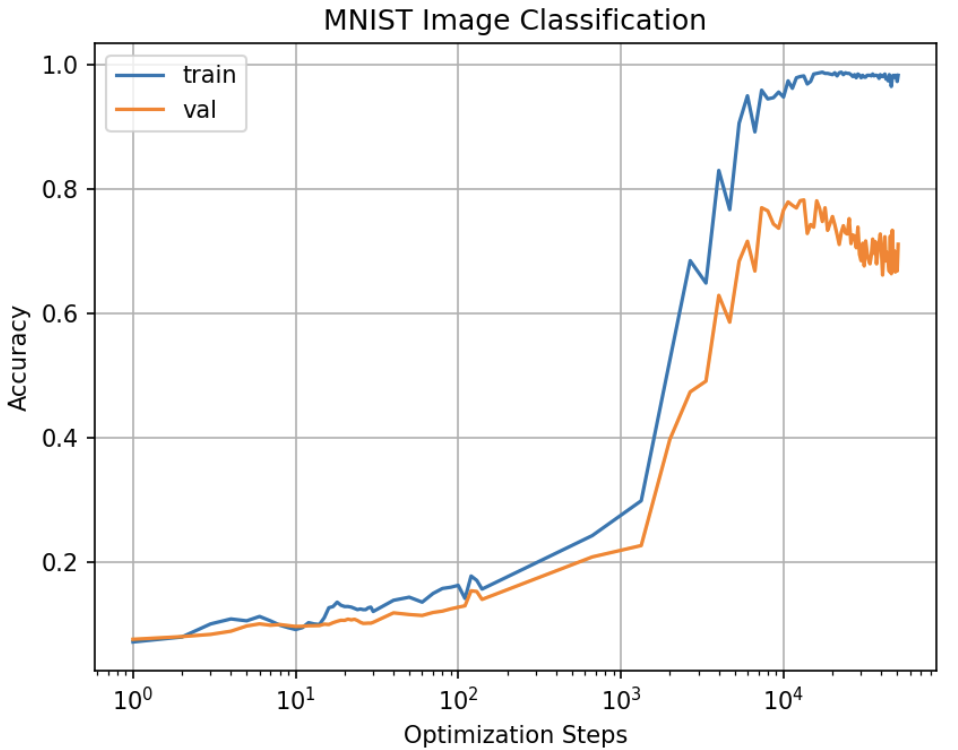
First, I changed the number of layers to 4 and 5 and tested the performance. While train acc and val acc increased simultaneously, the number of steps required to significantly increase train acc and val acc rised from \(10^3\) to around \(10^4\). This phenomenon was quite puzzling, and I speculated that it was due to the magnifying low-varying gradient component.
However, there’s still some interesting results of the experiment.


We can see that the network experienced sharper increase at \(10^4\) steps.
GrokFast - effect of network width
Next, I want to test the effect of network width on GrokFast performance, with the setup of 3 layers of network.

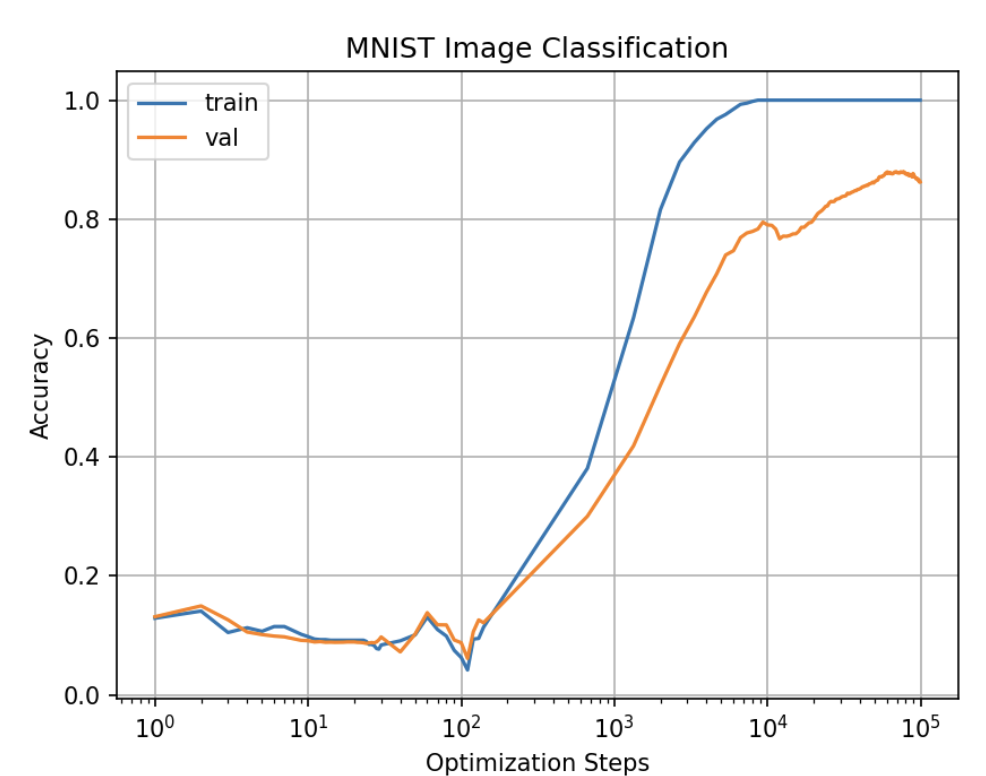
Based on the observation above, I conclude that network width can help network regain its val accuracy after the mysterious drop in val acc.
Combination with LoRA
Due to the phenomenon, I planed to use Grokfast on LoRA. Specifically, using the gradient update code on matrix A and matrix B can work maybe. However, the first test result was confusing.
The first setup is traditional 3 layer + 200 hidden size. GrokFast implemented MA optimizer, and here’s the result
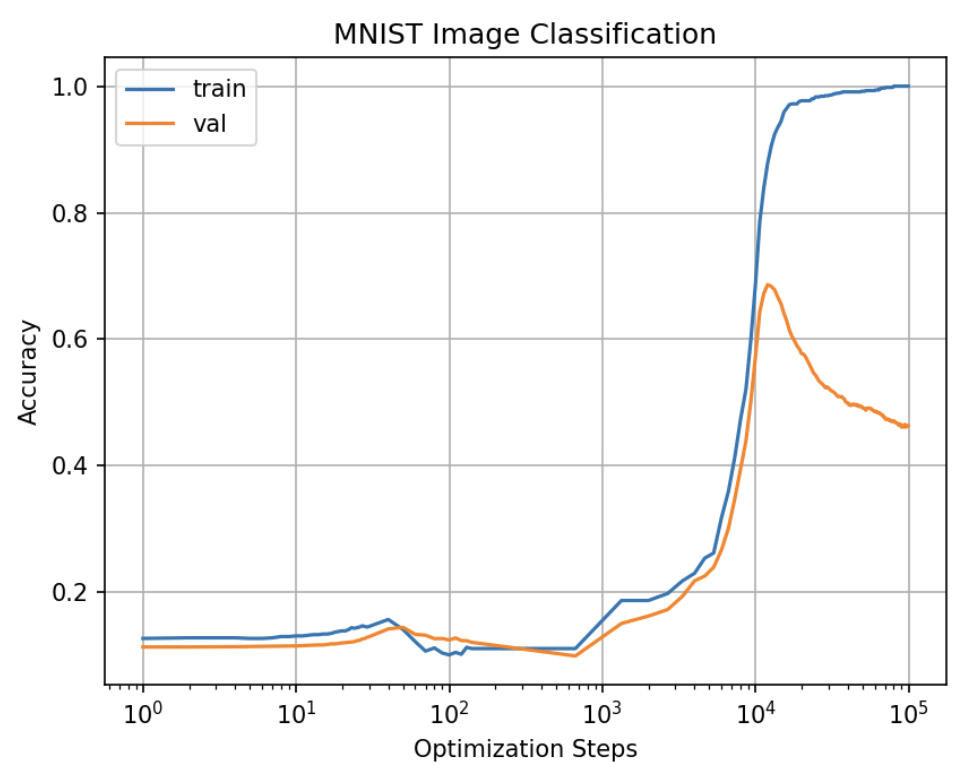
While val acc and train acc climbed up together at around 10^4, val acc suddenly dropped and continued to decrease until the end of training time.

For ema optimizer, the val acc sharply increase at \(10^4\) steps and then increases at a very slow pace.